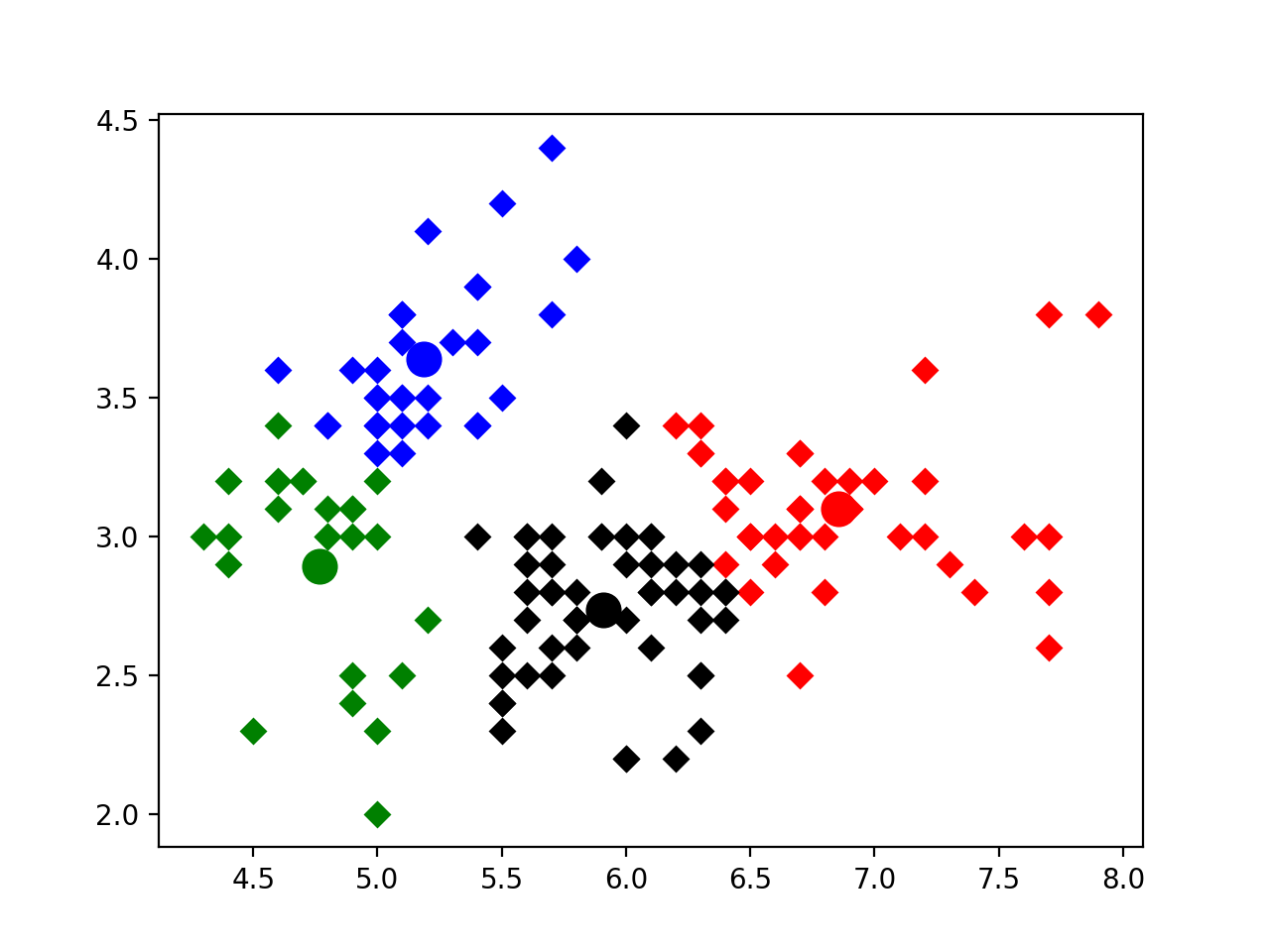
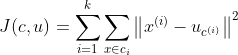classKMeans: def__init__(self, data) -> None: self.data = data
defconverged(self, c1, c2): set1 = set([tuple(c) for c in c1]) set2 = set([tuple(c) for c in c2]) return set1 == set2
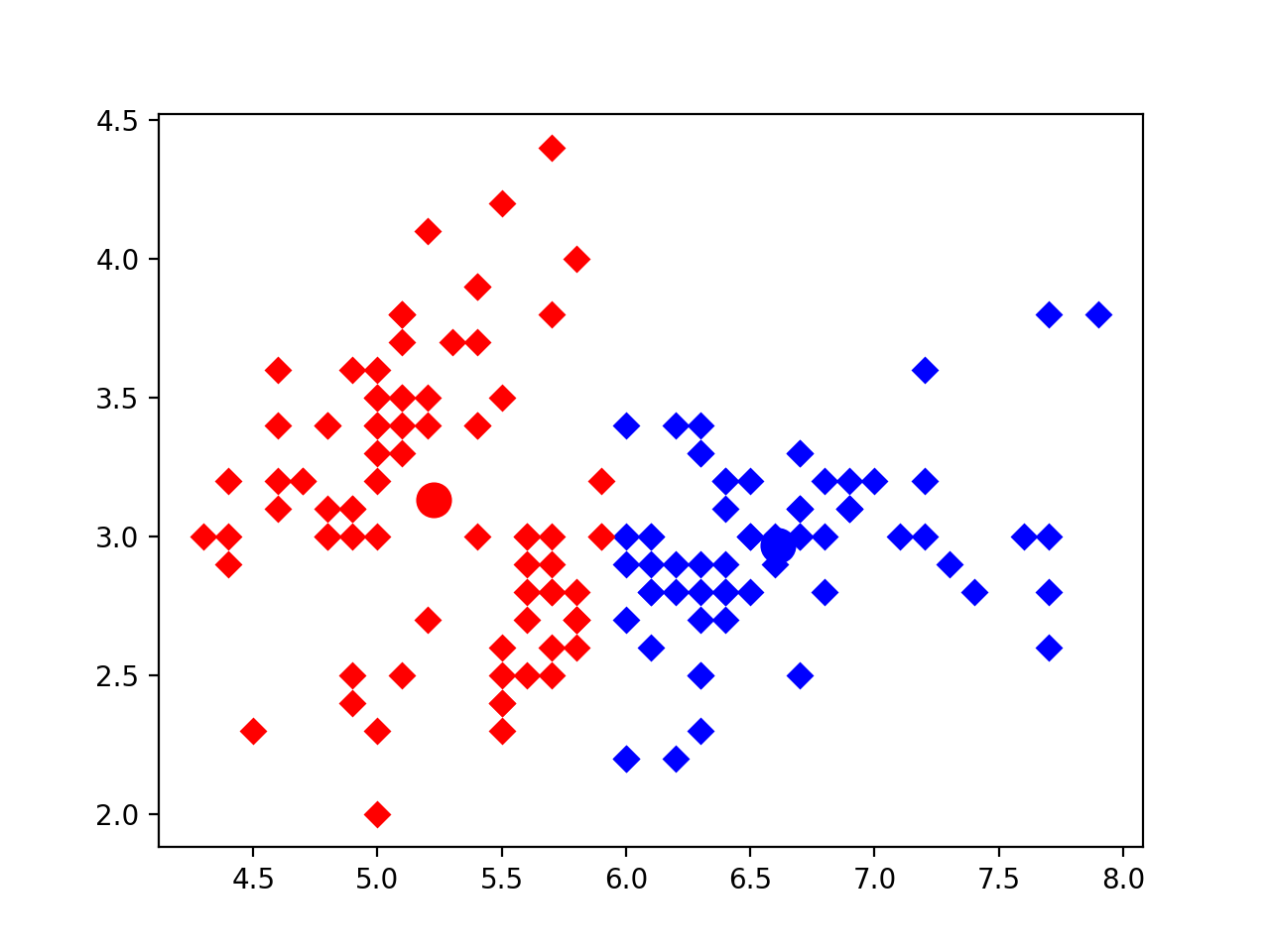
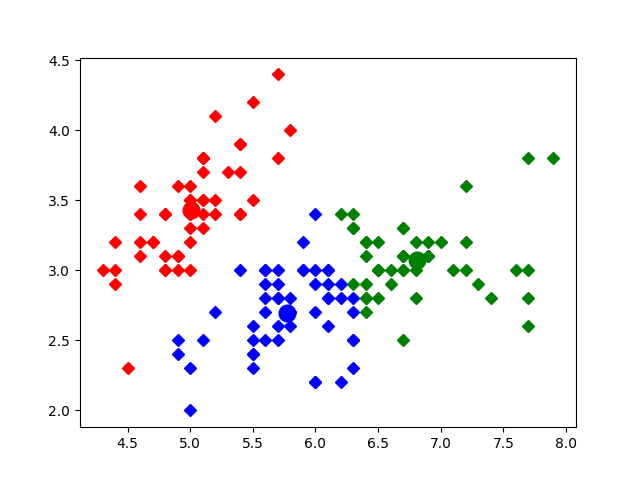
defcalc_kmeans(self, k=2): data = self.data n = data n = data.shape[0] # number of entries centroids = randam_centroid(data, k) label = np.zeros(n, dtype=int) # track the nearest centroid assement = np.zeros(n) # for the assement of our model converged = False
whilenot converged: old_centroid = np.copy(centroids) for i inrange(n): min_dist = np.inf for j inrange(k): dist = distance(data[i], centroids[j]) if dist < min_dist: min_dist = dist label[i] = j assement[i] = distance(data[i], centroids[label[i]])**2
# update centroid for m inrange(k): centroids[m] = np.mean(data[label==m], axis=0) converged = self.converged(centroids, old_centroid) return centroids, label, np.sum(assement)